発表資料はこちらになります。 AWS re:Inventの報告会なのに、完全に趣味によりすぎてしまいました...!!!
AWS re:invent 2018 サービスアップデート1行まとめ
ML系
Amazon Personalize eコマースなどでレコメンドができるようになるサービス。今までのサービスと異なり、自分たちの持っているデータを学習データとしてINPUTさせることができる。データはS3 or Amplify から送信可能。
Amazon Forecast 時系列データの予測。過去の売上などから、将来の売上を予測したりする。自分たちのデータを食わせることが可能
Amazon Comprehend Medical Amazon ComprehendというNLサービスの拡張。メディカル向けのチューニングが行われている。医療分野に対応。
Amazon Translate Custom Terminology Amazon Translateという翻訳サービスで、カスタム語彙が登録できるようになった。
ML Models in AWS Marketplace 機械学習モデルのマーケットプレイス。どこかの企業が作った出来合えのアルゴリズム・モデルを利用して、色々できるようになる
Amazon SageMaker Ground Truth データのアノテーションをサポートしてくれるサービス。アノテートするためのUIをいい感じに作ってくれる。実際にアノテートするのは人間。
SageMaker Neo SageMakerで作成したモデルを、EC2 インスタンスやGreegranss デバイス等のそれぞれのデバイスで最適に実行できるように変換する。それによって、モデルの効率をサイズ・速度の両面で改善する。OSSで公開中。
フレームワーク:Tensorflow, Apache MXNet, PyThorch デバイス:EC2 / ラズベリーパイ
Amazon Elastic Inference GPUリソースを安く利用するためのサービス。 Px 系のインスタンスを使わなくても、必要なときにCx系インスタンスにEIAをアタッチすればGPUリソースを一時的に付与して利用することができるっぽい。
SageMakerの画像認識にセマンティックセグメンテーションが追加 特定の画像に対して、ピクセル単位で画像領域を判断可能になった
Amazon SageMaker RL 強化学習をサポートする SageMakerの拡張。AWS RoboMakerや DeepRacer, Sumerianをシミュレーターとして利用可能。
Database
Amazon QLDB フルマネージドな元帳データベース。すべてのデータ変更を正確に順序づけられたエントリーとして格納
Amazon Managed Blockchain Hyperledger FabricとEthereum* を仕様したフルマネージドなブロックチェーンネットワークサービス。
Amazon Timestream 大量に発生する時系列データに特化したDB。RDBMSの10/1コスト、1000倍の性能で時系列データを扱える。
DynamoDB Transactions
DynamoDBで、複数アイテム・テーブルに対してACIDトランザクションをサポート。 Serializableでロックは取らない。頻繁に同じ行をrockして取り合うようなものには向かない。
DynamoDB On-Demand DynamoDB でPay-per-Requestモデルの請求モードが選択可能になった。
Amazon Aurora Global Database MySQL 5.6 互換。異なるリージョンのリードレプリカを、1秒未満の低レンテンシでのレプリケーション
Serverless
Amazon Aurora Serverless Data API Aurora Serverless へのアクセスについて、HTTPSエンドポイントが追加。VPCにアクセスすることなく Auroraを利用可能。
Lambda Layers Lambda間でロジックを簡単に共有できるもの。
AWS Step Functions API Connectors
ECS, DynamoDB, AWS Batch等々のサービスについては、Lambdaで書かなくても StepFunctionsから直接色々実行できるようになる
- ALBがLambdaに対応しました
- LambdaのRuntimeにRuby 2.5が追加されました
Storage
AWS DataSync マイグレーションやアップロード、バックアップ/DRにおけるデータ転送の加速と自動化を実現する
Glacier Deep Archive Deep ArchiveはGlacierよりもさらにコストを抑えることができるもの。 Glacierとの差分がよく分からぬ。
EFS Infrequent Access Storage Class 30日間くらいアクセスされないファイルを、自動でこのクラスに割り当てる。安くなる。
Automatic Cost Optimization for Amazon S3 Intelligent Tiering S3の拡張。AWSの方でパターンを見つけて、コスト最適になるように自動的にストレージクラスを選ぶ。
AWS Transfer for SFTP SFTPでS3のバケットにupload可能。AWSの機能で認証できる
Amazon FSx for Windows Server WindowsのファイルサーバーをAWSで構築可能。セキュリティの要件も日本のPCI/ISOに対応してるらしい
マイクロサービス
AWS Cloud Map マイクロサービス間の依存関係を把握するためのもの
AWS App Mesh マイクロサービス向けのサービスメッシュを提供する。無料
アカウント管理やセキュリティ
AWS Control Tower マルチアカウントに対応したセキュアな環境を簡単に設定・管理可能
AWS Security Hub GuardDutyやInspector、3rd Partyのログを一元管理できる。
AWS Transit Gateway 複数のアカウントで作成された複数のVPCを、中央で集約して管理することができるようになる
Amazon CloudWatch Log Insights CloudWatchでElasticsearch + Kibanaみたいな使い方ができるようになるらしい。
ネットワーク
AWS Global Accelerator 複数リージョン向けのアプリケーションのパフォーマンスの向上を容易にする。 一番近いリージョンのELB, EIPに自動で割り振るようにする。
その他
AWS Outposts AWSインフラストラクチャをオンプレミスで実行できるようになる。 EC2, EBS、RDS, ECS, EKS, SageMaker, ERMが対応している。
AWS Well-Architected Tool 現在のAWSベスト・プラクティスに照らしてワークロードを確認し、アーキテクチャを改善する方法を教えてもらう。
AWS Lake Formation データレイクを簡単に作ることができるようになるサービス
AWS Elemental Media Connect ビデオのライブストリーミングができるサービス
AWS Re:invent 2日目のKeynoteまとめ
- Lambda の公式 Runtimeに Ruby 2.5が追加されました
- Lambda Layersによって、Lambda間でロジックを簡単に共有できるようになりました
- Lambdaで Custom Runtimeを設定することができるようになり、好きな言語で書くことができるようになりました
- Step Functionsが、新たに8つのAWSサービス(ECS, AWS Batch, DynamoDB, Glue, SageMaker, etc )をサポートしました
- AWSにおいて、設計レビューをするサービスができました
- ALBがLambdaに対応しました
- API Gatewayが websocketに対応しました
(TypeScriptで書かれてWebpackでビルドされた) CloudFunctionsのエラー通知をわかりやすくしてみた
やりたいこと
stack driver error reportのエラーの内容をもう少しわかりやすくしたい。
やること
GitHub - prisma/serverless-plugin-typescript: Serverless plugin for zero-config Typescript support
ここを参考に node-sourcemap-supportを導入した。
https://firebase.google.com/docs/functions/typescript?hl=ja
ここを見ると、Firebaseでは index.js.map も一緒にdeployできると書いてあるが、cloud functions単体ではそういった記述を確認できなかったので、少し古いが上記のtopicに書かれていた通りの方法で実装した。serverless frameworkじゃなくても上手くいくか分からなかったがとりあえず試してみて、上手くいった。
具体的な変更内容
npm install source-map-support
// この一行を追加 import "source-map-support/register";
module.exports = {
...
devtool: 'source-map', //<= これを追加
...
}
これだけ。
結果
stack driver error traceで見たエラーメッセージを比較する。
before
ReferenceError: atob is not defined at t.HistoryAppender (index.js:593) at t.history_appender (index.js:424) at (/worker/worker.js:756) at <anonymous> at process._tickDomainCallback (next_tick.js:228)
どこのコードで問題があったのか全くわからない。
after
ReferenceError: atob is not defined at parse (/srv/webpack:/node_modules/@google-cloud/bigquery/src/index.js:5) at t.history_appender (index.ts:49) at (/worker/worker.js:756) at <anonymous> at process._tickDomainCallback (next_tick.js:228)
index.ts: 49行目の処理に問題があることがわかるようになった。
その他メモ
- どのくらい深い階層まで追えるのかまだ分かっていない
- build後のファイルサイズが大きくなっている訳ではない
// before ls -alh index.js -rw-r--r-- 1 shuhei.morioka staff 5.5M 11 12 21:24 index.js // after ls -alh index.js -rw-r--r-- 1 shuhei.morioka staff 5.5M 11 12 21:15 index.js
他に良い方法をご存知の方いれば教えてください〜
gcloudコマンドを実行するGCPのアカウントを切り替える
忘れないようにメモ。
例えば、before-selmertsx プロジェクトから、test-selmertsx プロジェクトへと切り替えるとする。
そのときの手順は下記の通り
configurationsの作成
gcloud config configurations create test-selmertsx gcloud config configurations activate test-selmertsx
プロジェクトの設定をする
下記コマンドでリージョンやアカウントの設定をします。
gcloud config set compute/region asia-northeast1 gcloud config set compute/zone asia-northeast1-a gcloud config set core/account selmertsx@gmail.com gcloud config set core/project test-selmertsx
そして gcloud config list で設定確認。
$ gcloud config list [compute] region = asia-northeast1 zone = asia-northeast1-a [core] account = selmertsx@gmail.com disable_usage_reporting = True project = test-selmertsx Your active configuration is: [test-selmertsx]
プロジェクトを有効にする
gcloud auth login を実行するとブラウザが立ち上がって認証する。それで終了。
$ gcloud config configurations list NAME IS_ACTIVE ACCOUNT PROJECT DEFAULT_ZONE DEFAULT_REGION before-selmertsx True selmertsx@gmail.com before-selmertsx asia-northeast1-a test-selmertsx False selmertsx@gmail.com test-selmertsx asia-northeast1-a asia-northeast1
元のプロジェクトに戻す
$ gcloud config configurations activate before-project Activated [before-project].
Cloud FunctionsとCloud Schedulerを利用してDatadogで監視しているホスト数を通知させてみた
作ったもの
指定された期間のDatadogの監視台数について、最小,最大,合計(ホスト数×時間)を算出してSlackに通知してくれるCloudFunctionsを作成しました。そのCloudFunctionsはCloud Pub/Subで実行され、Cloud SchedulerはそのCloud Pub/SubのTopicを一日一度実行してくれます。

コードはこちらです。 https://github.com/selmertsx/datadog_slack_report
この資料に記載されていること
- Cloud SchedulerからCloud Pub/Subを実行する方法
- DatadogでのRollup functionの使い方
- ※ Cloud Functionsに関する詳細な説明はしません。
CloudFunctionsを実行するための方法については、こちらの記事を参照してください。
https://qiita.com/selmertsx/items/31b10bfc4b72b05627e1 https://qiita.com/selmertsx/items/27686e51b4471eaf8c86
作った理由
- 今いる企業では複数のプロダクトでDatadogを利用してリソースの監視を行っていません
- Datadogでの監視はアカウントを分けていません
- サーバーメトリクスは企業の資産であり、すべてのエンジニアが隣のプロダクトのサーバーメトリクスや監視方法を見て学ぶことができるように、敢えてアカウントは分けないようにしています
- ちょっと声を掛けて見せて貰えばいいでないという声はあるかと思いますが、気になったときに誰の手も煩わせずに確認できるようにしたいという意図でそうしています
- アカウントを分けないで運用をしていると、プロダクト毎のコストを集計する必要がある
- コストの集計は自動でやってしまいたい
- 最近でた Cloud Schedulerを使ってみたい
事前準備
- 監視したいリソースにタグ付けをしてください
- 今回は
product: xxxとタグ付けをしました - タグの付け方はこちらの資料を参照してください
- もし僕のコードをそのまま動かす場合は、こちらのリポジトリをcloneしておいてください
タグ付けを行ったら次の準備に進んでください。
DatadogでのQueryの実行
DatadogではAPIを実行して、メトリクスを取得することができます。さらに、それらメトリクスに対して様々な計算処理を入れることも可能です。その実行方法については、こちらの資料に記載されています。
さて、シンプルに各プロダクト毎のホスト数をAPIで取得したい場合、count:system.cpu.user{*} by {product}のようなクエリになります。ECインスタンスのメトリクスは5分毎にagentから送信されているため、1日分のデータを取得してしまうと12 * 24 * プロダクト数分のデータが必要になってしまいます。Datadogの課金体系から考えても、1時間未満の粒度でのデータは取得する必要がありません。そのため、不要なデータを削ぎ落とす必要があります。今回はRollup関数を使って、データを1時間単位で丸め込んでから取得しました。これによって24*プロダクト数分のデータにすることができました。Rollup関数の説明はこちらになります。抜粋した文書が下記になります。
Rollup The function takes two parameters, method and time: .rollup(method,time) The method can be sum/min/max/count/avg and time is in seconds. You can use either one individually, or both together like .rollup(sum,120).
この説明通りにクエリを作成してみると、count:system.cpu.user{*} by {product}.rollup(count, 3600) という形になりました。TypeScriptのコードは下記のようになります。
// https://github.com/selmertsx/datadog_slack_report/blob/master/src/DatadogClient.ts#L28 public async countHosts(from: string, to: string): Promise<DatadogHostMetrics[]> { const params: CountHostRequest = { api_key: API_KEY, application_key: APP_KEY, from, query: `count:system.cpu.user{*} by {product}.rollup(count, 3600)`, to, }; const res: DatadogQueryReponse = await this.request.get("/query", { params }); return res.data.series.map((product: SeriesMetrics) => { const pointlists: PointList[] = product.pointlist.map((point: number[]) => { return { unixTime: point[0], count: point[1] }; }); return { product: product.scope, pointlists } }); }
僕のコードの中にDatadogのAPIで帰ってくるレスポンスの型(の一部)を記載しておきましたので、データの中身について気になる方は目を通されると良いでしょう。
Cloud Functionsのデプロイ
Google Cloud Pub/SubをトリガーにCloud Functionsを起動する設定をしていきます。Google Consoleからdatadog_reportというtopicを作成し、下記のコマンドでCloud Functionsをデプロイしましょう。
gcloud beta functions deploy datadog_handler \ --region=asia-northeast1 \ --stage-bucket=datadog_report \ --trigger-event=google.pubsub.topic.publish \ --trigger-resource=datadog_report \ --runtime=nodejs8
Cloud FunctionsのトリガーとしてCloud Pub/Subを利用する方法については、このドキュメントに詳細が記載されています。
Cloud Schedulerの設定
GCPのConsoleから、cloud schedulerを開いてみましょう。そこでcreate jobを選び、下記のように設定をします。ここでFrequencyが実行頻度を設定する部分です。cronと同じフォーマットで実行する頻度を設定することができます。そしてTargetがトリガーの設定部分です。ここではApp Engineのアプリケーション、Cloud Pub/Sub, HTTP Requestの3つを設定することができます。今回のCloudFunctionsはPub/Subをトリガーにしているので、ここではPub/Subを指定しておきましょう。
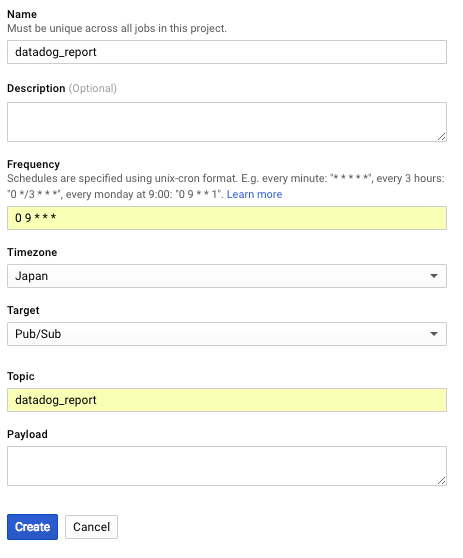
create ボタンを押せば終了です。気になるお値段ですが、こちらのドキュメントによると1人あたり3ジョブまで無料ということです。
動作確認

すぐに動作確認をしたいので、上記画面のRun now ボタンをクリックし、Pub/SubのTopicに対してメッセージを送ってみましょう。するとSlackに下記のようにメッセージが送信されます。
以上で、Cloud FunctionsとCloud Schedulerを利用してDatadogで監視しているホスト数を通知させることができました。今後は、集計期間をpub/subのメッセージで設定できるようにするなど機能を追加していく予定です。もし、使ってくださる方がいて、追加で欲しい機能などございましたら、お気軽にIssue登録おねがいします〜
Azure ADとG Suiteのグループを同期させる
モチベーション
- メーリスの設定を自動でして欲しい
- Google Drive内の資料の閲覧権限を自動かつ適切に付与したい
- 誰がどのようなグループに所属し、どのような権限を持つかはAzure ADで制御したい
やり方の方針
- Azure ADとG SuiteのGroupを同期させる
- Azure ADをマスターとし、G Suite内でグループの設定変更はしない
- Azure ADの動的グループメンバーシップという便利機能を使って、グループに所属するメンバーを自動で追加・削除する
本資料で記載すること
- AzureAD と G Suiteのグループを同期させるところまで
- 動的グループメンバーシップについては次回
前提条件
- Azure ADのEnterprise Application設定権限を持っている
- G Suiteの特権管理者権限を持っている
やり方
基本的にこちらのドキュメントどおりに設定します。ここでは、上記ドキュメントの補足のみを行います。
Configure automatic user account provisioning
基本的にドキュメントの通り設定すれば良いです。
手順7: Admin API Privileges
手順に記載されている画像を見ると全てのチェックボックスがチェックされているように見えますが、僕が見た画面は何もチェックされていませんでした。

不安はあったものの、User画面から自分の権限を確認したら、ちゃんと全ての権限があったのでとりあえず先に進みました。それで問題なかったです。

手順10: Provisioningの設定
もし、G Suiteと同期するAzure ADのグループを絞る必要があるのであれば、
Provisioning の設定をする前に同期対象のグループを指定する必要があります。Users and groups タブからこんな形でユーザー・グループを設定しました。

手順13: Azure ADにG Suiteの権限委譲
Azure ADからの許可を求められる画面イメージが、サンプル画像と違ったので一応載せておきます。

手順17: Mappings
今回はGroupの同期がしたかったのでMappingsの設定を Synchronize Azure Active Directory Groups to GoogleApps にしました。また、SettingsのScopeについては、任意のグループのみを同期したいのであれば Sync only assigned users and groups に設定する必要があります。

結果
- グループが問題なく作られている
- グループ内にメンバーも所属している

疑問点
- グループのオーナーを指定する場所が無かった
- グループのメールアドレスをどのように指定するのか